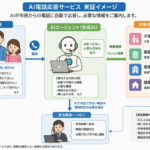
音声認識AIは、音声をテキストや指示に変換する技術です。この技術は、日常生活からビジネスまで幅広い分野で活用されています。この記事では、音声認識AIの仕組みや活用事例、メリット・デメリット、そして今後の可能性について詳しく解説します。音声認識AIについて知りたい方、導入を検討している企業担当者にぜひ読んでほしい内容です。
目次
音声認識AIの基本構造を徹底解説
音声認識AIは、音声を正確に解析してテキストや指示に変換するために、複数の高度な技術を組み合わせています。このセクションでは、各プロセスをさらに詳しく解説し、音声認識の仕組みを深く理解できるように説明します。
音声入力とデジタル化
音声認識AIはまず、音声をデジタル信号に変換するプロセスから始まります。
- 音声の収集
マイクロフォンを通じて、周囲の音を取り込みます。この段階での品質が、認識精度に大きく影響します。そのため、高性能なノイズキャンセリング技術がしばしば使用されます。 - デジタル化のプロセス
アナログ音声波形をデジタルデータ(0と1の信号)に変換します。この際、サンプリングレート(1秒間に記録する音声信号のデータ点数)が重要です。一般的な設定では、16kHz(16,000点/秒)や44.1kHz(CD品質)が用いられます。 - 前処理
ノイズ除去や音量正規化を行い、解析しやすい形に整えます。また、「フレーム分割」と呼ばれる工程で音声を短い時間単位(通常20~40ms)に分割します。
音響モデルによる音素解析
音響モデルは、音声信号を音素に変換する重要な役割を果たします。音素とは、言語を構成する最小単位の音声要素です。
- 特徴量抽出
フレームごとの音声データから、周波数成分やエネルギー分布を計算します。この工程では、メル周波数ケプストラム係数(MFCC)やスペクトログラムなどがよく用いられます。 - 音響モデルの動作
特徴量をもとに、確率的にどの音素に該当するかを推定します。この際、ディープラーニングを活用したニューラルネットワーク(特に畳み込みニューラルネットワークやリカレントニューラルネットワーク)が主流です。 - HMM(隠れマルコフモデル)
過去にはHMMが音響モデルの主流でした。現在はニューラルネットワークが置き換えつつありますが、一部のシステムでは依然としてHMMが活用されています。
言語モデルによる文脈解析
音素が認識された後、それを適切な単語やフレーズに変換するのが言語モデルの役割です。
- 言語モデルの種類
- 統計的言語モデル(N-gram)
過去の単語列から次の単語を予測するモデルです。例えば、「私は」の後に「リンゴを食べた」という文脈を確率的に予測します。 - ニューラル言語モデル
ディープラーニングを活用したモデルで、特にトランスフォーマーアーキテクチャ(例:BERT、GPT)が高い精度を誇ります。
- 統計的言語モデル(N-gram)
- 文脈の考慮
単語の意味や文法的なつながりを考慮し、音素の組み合わせが自然な単語列になるよう補正します。 - 誤認識補正
よくある誤認識パターン(同音異義語など)を、事前に学習させたデータを基に修正します。
テキストまたはコマンド出力
最終段階では、解析された音声がテキストとして出力されるか、特定のアクションに変換されます。
- テキスト出力
文字起こしや字幕生成の場合、認識結果をそのままテキストデータとして出力します。 - コマンド変換
スマートスピーカーや音声アシスタントの場合、「電気をつけて」のような命令を解析し、IoTデバイスに具体的な操作指示を送ります。 - 出力の精度向上
出力精度をさらに高めるために、カスタム辞書や専門用語リストを導入する場合もあります。
音声認識AIの学習方法を詳しく解説
音声認識AIが高精度な認識を実現するためには、膨大なデータを活用した効果的な学習が欠かせません。このセクションでは、音声認識AIの主な学習方法である「教師あり学習」「無教師学習」「強化学習」、およびそれらを支えるディープラーニングの技術について詳しく解説します。
教師あり学習
教師あり学習は、最も一般的な学習方法で、入力(音声データ)と対応する正解(テキストやタグ)をセットで与えることでAIを訓練します。
- プロセス
- 音声データと対応するテキスト(例えば「こんにちは」という音声と「こんにちは」という文字列)をペアとしてAIに提供します。
- AIは音声特徴量とテキストの対応関係を学習し、新しいデータに対しても同様のマッピングを予測できるようになります。
- 特徴
教師あり学習は大量の正確なデータが必要ですが、明確な正解を学習するため精度が高くなりやすいです。 - 音声認識での使用例
スマートスピーカーや音声文字起こしシステムの基盤を構築する際に利用されます。
無教師学習
無教師学習は、正解データを必要とせず、AIがデータの中からパターンや特徴を自動で見つけ出す学習方法です。
- プロセス
- 大量の音声データをAIに与えます。
- AIは音声データの構造や類似性に基づいて、データを分類・クラスタリングします。
- 特徴
無教師学習は正解データを準備する手間が省けるため、大量のラベル付けされていないデータを活用できます。ただし、精度を向上させるには追加の手法(自己教師あり学習など)が必要です。 - 音声認識での使用例
特定の言語に特化しない音声モデルや、新しい音声データへの適応を目的とした事前学習で活用されます。
強化学習
強化学習は、AIが環境とのやり取りを通じて試行錯誤しながら、最適な行動を学習する方法です。
- プロセス
- AIに初期設定のモデルを与えます。
- 音声認識結果に基づき、環境(ユーザーやシステム)から「報酬」または「罰」を受け取ります。
- AIは報酬を最大化する方向でモデルを更新します。
- 特徴
リアルタイムでの適応が可能で、特定のユーザーや状況に合わせた認識精度の改善が期待できます。 - 音声認識での使用例
コールセンターなど、ユーザーからのフィードバックを元に認識精度を向上させるシステムに利用されます。
ディープラーニングの技術と活用
ディープラーニングは音声認識AIの中核技術で、音声データを処理する高度なアルゴリズムを提供します。
1. ニューラルネットワークの種類
- 畳み込みニューラルネットワーク(CNN)
音声の時間的・空間的な特徴を抽出するために使用されます。特にスペクトログラム(音声の周波数特性を視覚的に表現したもの)から特徴を抽出する際に効果的です。 - リカレントニューラルネットワーク(RNN)
音声データのような時系列データに適しており、過去の情報を保持して次のデータ処理に活用します。- **LSTM(長短期記憶)やGRU(ゲート付きリカレントユニット)**がよく使用されます。
- トランスフォーマー
音声認識分野では近年注目されており、特に自己注意機構(Self-Attention)を使うことで長期的な文脈を捉えるのに優れています。
2. ハイブリッドモデル
- 音響モデルと言語モデルを組み合わせ、音声信号から文脈を理解した認識を実現します。
- 例:Googleの音声認識エンジンでは、トランスフォーマーモデルを活用して音響的な特徴と文脈的な特徴を統合しています。
学習データとデータ増強(Data Augmentation)
学習データの質と量は音声認識AIの性能に直結します。以下の手法で学習データを強化します。
- データ拡張(Augmentation)
ノイズ追加、音程や速度の変化などを人工的に加え、データの多様性を高めます。 - 自己教師あり学習
ラベル付けされていないデータに擬似ラベルを付与し、無駄なく学習を進める手法です。 - マルチスピーカー対応
多様な話者のデータを収集し、異なるアクセントや話し方への耐性を向上させます。
これからの音声認識の進化と未来
音声認識AIは、これまでの進化により多くの分野で活用されていますが、技術の進歩はさらに加速しています。ここでは、今後の音声認識AIの進化と期待される可能性について解説します。
1. 感情認識の統合
これからの音声認識技術では、単なる言語認識にとどまらず、話者の感情や意図を解析する「感情認識」が重要になります。話者のトーンや声の強弱を分析することで、喜びや怒り、不安といった感情を理解し、より適切な反応が可能になります。これにより、カスタマーサポートやヘルスケア分野での応用が期待されています。
2. ゼロショット学習と少量データ学習
従来の音声認識AIは膨大なデータを必要としていましたが、今後はゼロショット学習や少量データ学習の技術が普及し、学習データが少なくても高精度の認識が可能になります。これにより、新しい言語や方言への対応が迅速に行えるようになります。
3. ノイズ環境での認識性能向上
音声認識AIは現在もノイズの多い環境での精度向上が課題となっています。これからの技術では、ノイズキャンセリングや指向性マイクの進化に加え、環境ノイズを適応的に学習するアルゴリズムが実用化され、雑音下でもスムーズな音声認識が実現するでしょう。
4. マルチモーダル音声認識
音声だけでなく、映像やテキストなど他の情報源と統合して音声を認識する「マルチモーダル音声認識」が進化します。例えば、会議システムでは、話者の表情やスライド資料と音声を関連付けることで、内容の理解を深められるようになります。
5. リアルタイム翻訳の精度向上
リアルタイムで多言語の音声を翻訳する技術は、国際的なコミュニケーションや観光業で需要が高まっています。将来的には、音声認識と翻訳、音声合成を統合し、即座に自然な翻訳を行うシステムが普及すると考えられます。
6. IoTおよびスマート環境との連携
音声認識AIは、家庭やオフィスのIoTデバイスとさらに深く連携することで、よりシームレスな体験を提供します。例えば、部屋に入るだけで「電気をつけて」「エアコンの温度を下げて」といった指示が自然に通る環境が整備されるでしょう。
7. 個別化された音声認識
話者個人の声の特徴を学習し、ユーザーごとに最適化された音声認識技術が進化します。これにより、アクセントや発音の違いを考慮した、より精度の高い認識が可能になります。例えば、家庭内で複数人がスマートデバイスを使う際に、個別の声に対応することで誤認識を防げます。
8. プライバシー保護技術の強化
音声データを扱う際のプライバシー問題に対処するため、音声認識AIの分散型学習やエッジコンピューティングが進化します。これにより、データをクラウドに送信せずにデバイス内で処理する仕組みが普及し、プライバシーの確保と認識精度を両立させる技術が期待されています。
9. 自動生成型AIとの連携
音声認識AIが、テキストや音声を生成する生成型AI(例:ChatGPT、音声合成技術)と連携することで、音声での双方向コミュニケーションがより自然になります。例えば、音声認識でユーザーの質問を理解し、その場で自然な音声で回答を提供する仕組みが強化されます。